 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Finetuner's Fallacy: When to Pretrain with Your Finetuning Data
Mar 17, 2026Real-world model deployments demand strong performance on narrow domains where data is often scarce. Typically, practitioners finetune models to specialize them, but this risks overfitting to the domain and forgetting general knowledge. We study a simple strategy, specialized pretraining (SPT), where a small domain dataset, typically reserved for finetuning, is repeated starting from pretraining as a fraction of the total tokens. Across three specialized domains (ChemPile, MusicPile, and ProofPile), SPT improves domain performance and preserves general capabilities after finetuning compared to standard pretraining. In our experiments, SPT reduces the pretraining tokens needed to reach a given domain performance by up to 1.75x. These gains grow when the target domain is underrepresented in the pretraining corpus: on domains far from web text, a 1B SPT model outperforms a 3B standard pretrained model. Beyond these empirical gains, we derive overfitting scaling laws to guide practitioners in selecting the optimal domain-data repetition for a given pretraining compute budget. Our observations reveal the finetuner's fallacy: while finetuning may appear to be the cheapest path to domain adaptation, introducing specialized domain data during pretraining stretches its utility. SPT yields better specialized domain performance (via reduced overfitting across repeated exposures) and better general domain performance (via reduced forgetting during finetuning), ultimately achieving stronger results with fewer parameters and less total compute when amortized over inference. To get the most out of domain data, incorporate it as early in training as possible.
ÜberWeb: Insights from Multilingual Curation for a 20-Trillion-Token Dataset
Feb 16, 2026Multilinguality is a core capability for modern foundation models, yet training high-quality multilingual models remains challenging due to uneven data availability across languages. A further challenge is the performance interference that can arise from joint multilingual training, commonly referred to as the "curse of multilinguality". We study multilingual data curation across thirteen languages and find that many reported regressions are not inherent to multilingual scaling but instead stem from correctable deficiencies in data quality and composition rather than fundamental capacity limits. In controlled bilingual experiments, improving data quality for any single language benefits others: curating English improves non-English performance in 12 of 13 languages, while curating non-English yields reciprocal improvements in English. Bespoke per-language curation produces substantially larger within-language improvements. Extending these findings to large-scale general-purpose training mixtures, we show that curated multilingual allocations comprising under 8% of total tokens remain remarkably effective. We operationalize this approach within an effort that produced a 20T-token pretraining corpus derived entirely from public sources. Models with 3B and 8B parameters trained on a 1T-token random subset achieve competitive multilingual accuracy with 4-10x fewer training FLOPs than strong public baselines, establishing a new Pareto frontier in multilingual performance versus compute. Moreover, these benefits extend to frontier model scale: the 20T-token corpus served as part of the pretraining dataset for Trinity Large (400B/A13B), which exhibits strong multilingual performance relative to its training FLOPs. These results show that targeted, per-language data curation mitigates multilingual interference and enables compute-efficient multilingual scaling.
When Should We Introduce Safety Interventions During Pretraining?
Jan 11, 2026Ensuring the safety of language models in high-stakes settings remains a pressing challenge, as aligned behaviors are often brittle and easily undone by adversarial pressure or downstream finetuning. Prior work has shown that interventions applied during pretraining, such as rephrasing harmful content, can substantially improve the safety of the resulting models. In this paper, we study the fundamental question: "When during pretraining should safety interventions be introduced?" We keep the underlying data fixed and vary only the choice of a safety curriculum: the timing of these interventions, i.e., after 0%, 20%, or 60% of the pretraining token budget. We find that introducing interventions earlier generally yields more robust models with no increase in overrefusal rates, with the clearest benefits appearing after downstream, benign finetuning. We also see clear benefits in the steerability of models towards safer generations. Finally, we observe that earlier interventions reshape internal representations: linear probes more cleanly separate safe vs harmful examples. Overall, these results argue for incorporating safety signals early in pretraining, producing models that are more robust to downstream finetuning and jailbreaking, and more reliable under both standard and safety-aware inference procedures.
DatBench: Discriminative, Faithful, and Efficient VLM Evaluations
Jan 05, 2026Empirical evaluation serves as the primary compass guiding research progress in foundation models. Despite a large body of work focused on training frontier vision-language models (VLMs), approaches to their evaluation remain nascent. To guide their maturation, we propose three desiderata that evaluations should satisfy: (1) faithfulness to the modality and application, (2) discriminability between models of varying quality, and (3) efficiency in compute. Through this lens, we identify critical failure modes that violate faithfulness and discriminability, misrepresenting model capabilities: (i) multiple-choice formats reward guessing, poorly reflect downstream use cases, and saturate early as models improve; (ii) blindly solvable questions, which can be answered without images, constitute up to 70% of some evaluations; and (iii) mislabeled or ambiguous samples compromise up to 42% of examples in certain datasets. Regarding efficiency, the computational burden of evaluating frontier models has become prohibitive: by some accounts, nearly 20% of development compute is devoted to evaluation alone. Rather than discarding existing benchmarks, we curate them via transformation and filtering to maximize fidelity and discriminability. We find that converting multiple-choice questions to generative tasks reveals sharp capability drops of up to 35%. In addition, filtering blindly solvable and mislabeled samples improves discriminative power while simultaneously reducing computational cost. We release DatBench-Full, a cleaned evaluation suite of 33 datasets spanning nine VLM capabilities, and DatBench, a discriminative subset that achieves 13x average speedup (up to 50x) while closely matching the discriminative power of the original datasets. Our work outlines a path toward evaluation practices that are both rigorous and sustainable as VLMs continue to scale.
Luxical: High-Speed Lexical-Dense Text Embeddings
Dec 11, 2025Frontier language model quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end language model data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at https://github.com/datologyai/luxical.
Unlocking Post-hoc Dataset Inference with Synthetic Data
Jun 18, 2025The remarkable capabilities of Large Language Models (LLMs) can be mainly attributed to their massive training datasets, which are often scraped from the internet without respecting data owners' intellectual property rights. Dataset Inference (DI) offers a potential remedy by identifying whether a suspect dataset was used in training, thereby enabling data owners to verify unauthorized use. However, existing DI methods require a private set-known to be absent from training-that closely matches the compromised dataset's distribution. Such in-distribution, held-out data is rarely available in practice, severely limiting the applicability of DI. In this work, we address this challenge by synthetically generating the required held-out set. Our approach tackles two key obstacles: (1) creating high-quality, diverse synthetic data that accurately reflects the original distribution, which we achieve via a data generator trained on a carefully designed suffix-based completion task, and (2) bridging likelihood gaps between real and synthetic data, which is realized through post-hoc calibration. Extensive experiments on diverse text datasets show that using our generated data as a held-out set enables DI to detect the original training sets with high confidence, while maintaining a low false positive rate. This result empowers copyright owners to make legitimate claims on data usage and demonstrates our method's reliability for real-world litigations. Our code is available at https://github.com/sprintml/PostHocDatasetInference.
OpenUnlearning: Accelerating LLM Unlearning via Unified Benchmarking of Methods and Metrics
Jun 14, 2025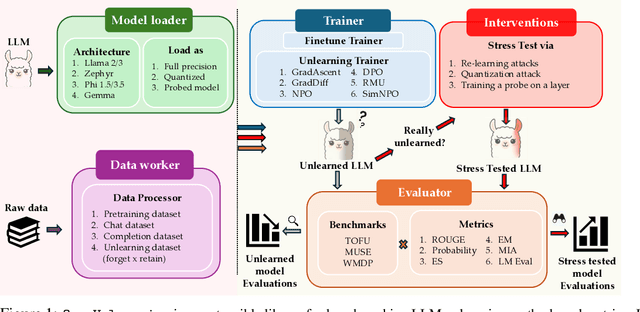



Robust unlearning is crucial for safely deploying large language models (LLMs) in environments where data privacy, model safety, and regulatory compliance must be ensured. Yet the task is inherently challenging, partly due to difficulties in reliably measuring whether unlearning has truly occurred. Moreover, fragmentation in current methodologies and inconsistent evaluation metrics hinder comparative analysis and reproducibility. To unify and accelerate research efforts, we introduce OpenUnlearning, a standardized and extensible framework designed explicitly for benchmarking both LLM unlearning methods and metrics. OpenUnlearning integrates 9 unlearning algorithms and 16 diverse evaluations across 3 leading benchmarks (TOFU, MUSE, and WMDP) and also enables analyses of forgetting behaviors across 450+ checkpoints we publicly release. Leveraging OpenUnlearning, we propose a novel meta-evaluation benchmark focused specifically on assessing the faithfulness and robustness of evaluation metrics themselves. We also benchmark diverse unlearning methods and provide a comparative analysis against an extensive evaluation suite. Overall, we establish a clear, community-driven pathway toward rigorous development in LLM unlearning research.
Safety Pretraining: Toward the Next Generation of Safe AI
Apr 23, 2025As large language models (LLMs) are increasingly deployed in high-stakes settings, the risk of generating harmful or toxic content remains a central challenge. Post-hoc alignment methods are brittle: once unsafe patterns are learned during pretraining, they are hard to remove. We present a data-centric pretraining framework that builds safety into the model from the start. Our contributions include: (i) a safety classifier trained on 10,000 GPT-4 labeled examples, used to filter 600B tokens; (ii) the largest synthetic safety dataset to date (100B tokens) generated via recontextualization of harmful web data; (iii) RefuseWeb and Moral Education datasets that convert harmful prompts into refusal dialogues and web-style educational material; (iv) Harmfulness-Tag annotations injected during pretraining to flag unsafe content and steer away inference from harmful generations; and (v) safety evaluations measuring base model behavior before instruction tuning. Our safety-pretrained models reduce attack success rates from 38.8% to 8.4% with no performance degradation on standard LLM safety benchmarks.
STAMP Your Content: Proving Dataset Membership via Watermarked Rephrasings
Apr 18, 2025Given how large parts of publicly available text are crawled to pretrain large language models (LLMs), data creators increasingly worry about the inclusion of their proprietary data for model training without attribution or licensing. Their concerns are also shared by benchmark curators whose test-sets might be compromised. In this paper, we present STAMP, a framework for detecting dataset membership-i.e., determining the inclusion of a dataset in the pretraining corpora of LLMs. Given an original piece of content, our proposal involves first generating multiple rephrases, each embedding a watermark with a unique secret key. One version is to be released publicly, while others are to be kept private. Subsequently, creators can compare model likelihoods between public and private versions using paired statistical tests to prove membership. We show that our framework can successfully detect contamination across four benchmarks which appear only once in the training data and constitute less than 0.001% of the total tokens, outperforming several contamination detection and dataset inference baselines. We verify that STAMP preserves both the semantic meaning and the utility of the original data in comparing different models. We apply STAMP to two real-world scenarios to confirm the inclusion of paper abstracts and blog articles in the pretraining corpora.
Understanding Hallucinations in Diffusion Models through Mode Interpolation
Jun 13, 2024



Colloquially speaking, image generation models based upon diffusion processes are frequently said to exhibit "hallucinations," samples that could never occur in the training data. But where do such hallucinations come from? In this paper, we study a particular failure mode in diffusion models, which we term mode interpolation. Specifically, we find that diffusion models smoothly "interpolate" between nearby data modes in the training set, to generate samples that are completely outside the support of the original training distribution; this phenomenon leads diffusion models to generate artifacts that never existed in real data (i.e., hallucinations). We systematically study the reasons for, and the manifestation of this phenomenon. Through experiments on 1D and 2D Gaussians, we show how a discontinuous loss landscape in the diffusion model's decoder leads to a region where any smooth approximation will cause such hallucinations. Through experiments on artificial datasets with various shapes, we show how hallucination leads to the generation of combinations of shapes that never existed. Finally, we show that diffusion models in fact know when they go out of support and hallucinate. This is captured by the high variance in the trajectory of the generated sample towards the final few backward sampling process. Using a simple metric to capture this variance, we can remove over 95% of hallucinations at generation time while retaining 96% of in-support samples. We conclude our exploration by showing the implications of such hallucination (and its removal) on the collapse (and stabilization) of recursive training on synthetic data with experiments on MNIST and 2D Gaussians dataset. We release our code at https://github.com/locuslab/diffusion-model-hallucination.